


Daily Article (October. 2021)
✨ 10월 1일 (금)
📰 정렬 알고리즘 정리 (Bubble, Selection, Insertion, Merge, Quick)
정렬 알고리즘 종류
- 버블정렬(Bubble sort)
- 선택정렬(Selection sort)
- 삽입정렬(Insertion sort)
- 병합정렬(Merge sort)
- 퀵정렬(Quick sort)
버블정렬(Bubble sort)
- 거의 모든 상황에서 최악의 성능을 보여주지만, 이미 정렬된 자료에서는 1번만 순회하면 되기 때문에 최선의 성능을 보여주는 알고리즘이다.
- 한번 순회할 때마다 마지막 하나가 정렬되므로 원소들이 거품이 올라오는 것처럼 보여서 버블정렬이라고 부른다.
- 비효율적인 정렬 방식으로 실무에서 거의 사용하지 않는다.
선택정렬(Selection sort)
- 주어진 자료들 중에 현재 위치에 맞는 자료를 찾아 선택하여 위치를 교환하는 정렬 알고리즘이다.
- 한번 순회를 돌게되면 알고리즘 상 전체 자료 중 가장 작은 값의 자료가 0번째 인덱스에 위치하게 되므로 그 다음 순회부터는 1번 인덱스부터 순회를 돌며 반복하면 된다.
- 선택정렬은 현재 자료가 정렬이 되어있던말던 무조건 전체 리스트를 순회해가며 검사하기 때문에 최선의 경우든 최악의 경우든 한결같이 $O(n^2)$의 시간복잡도를 가지고 있다.
삽입정렬(Insertion sort)
- 주어진 자료의 모든 요소를 앞에서부터 차례대로 정렬된 자료 부분과 비교하여 자신의 위치를 찾아 삽입하는 정렬이다.
- 삽입정렬은 최선의 경우 전체 자료를 한번만 순회하면 되기때문에 $O(n)$의 시간복잡도를 가지지만 최악의 경우 $O(n^2)$의 시간복잡도를 가진다.
병합정렬(Merge sort)
- 주어진 자료를 잘게 쪼갠 뒤 합치는 과정에서 정렬을 하는 알고리즘이다.
- 같은 방식으로 계속 반복하여 병합하고 있기 때문에 병합정렬은 보통 재귀함수로 구현한다.
- 병합정렬은 항상 $O(nlogn)$의 시간복잡도를 가지기 때문에 효율적이다.
퀵정렬(Quick sort)
- 병합정렬과 마찬가지로 분할정복을 통한 정렬방법이다.
- 병합정렬과의 차이점은 병합정렬은 분할 단계에서는 아무것도 하지않고 병합하는 단계에서 정렬을 수행하지만, 퀵정렬은 분할 단계에서 중요한 작업들을 수행하고 병합시에는 아무것도 하지않는다는 점이다.
✨ 10월 2일 (토)
📰 React Query로 서버 상태 관리하기
- React Query는 서버 상태(server state)를 관리하는 라이브러리다.
서버 상태
-
원격에 위치한 공간에 저장되며 앱이 소유하거나 제어하지 않는다.
-
데이터를 가져오고 업데이트하기 위해선 비동기 API가 필요하다.
-
다른 사람과 함께 사용하며, 내가 모르는 사이에 업데이트될 수 있다.
-
앱에서 사용하는 데이터가 “유효 기간이 지난” 상태가 될 가능성을 가진다.
-
React Query를 사용하려면 서버 데이터 처리 방식을 바꿔야 한다.
-
React에서는 redux, mobx같은 상태 관리 라이브러리를 사용한다.
-
React Query는 기본적으로 함수형 컴포넌트 안에서 훅 형태로 사용하며 서버 상태를 다른 장소에 저장할 필요가 없다.
캐싱 & 리프레쉬
- 소켓 통신을 사용한다면 서버 상태가 즉시 업데이트되겠지만 그렇지 않다면 주기적으로 업데이트해주는 기능을 직접 구현해야 한다.
- React Query는 useQuery 훅의 파라미터를 통해 API 데이터의 만료 시간, 리프레쉬 간격, 데이터를 캐시에서 유지할 기간, 브라우저 포커스시 데이터 리프레쉬 여부, 성공 or 에러 콜백 등 다양한 기능을 제어할 수 있다.
React Query 사용 방법
- fetching - 요청 중인 쿼리
- fresh - 만료되지 않은 쿼리. 컴포넌트가 마운트, 업데이트되어도 데이터를 다시 요청하지 않는다.
- stale - 만료된 쿼리. 컴포넌트가 마운트, 업데이트되면 데이터를 다시 요청한다.
- inactive - 사용하지 않는 쿼리. 일정 시간이 지나면 가비지 컬렉터가 캐시에서 제거한다.
- delete - 가비지 컬렉터에 의해 캐시에서 제거된 쿼리
✨ 10월 3일 (일)
📰 alert() 가 사라진다?
- 최근에 Google에서 cross-origin iframe 에서 alert(), confirm(), prompt()를 자사의 브라우저 Chrome의 기능에서 제외하도록 계획하고 있다고 발표했다.
이유?
-
현재 크롬은 iframe이 대화상자 api를 트리거 할 수 있다.
-
유저에게 썩 좋은 경험이 되지 못했다.
-
대화상자의 디자인이 달라 자칫 브라우저의 자체 UI 로 보일 수 있다.
-
이로 인해 사이트에서 특정메세지가 크롬에서 온 것처럼 가장하는 spoofing이 발생했다.
분위기?
- 구글이라는 한 회사가 웹 이라는 한 곳에 치중되어서는 안되는 플랫폼을 건드리는 행보를 보였기에 좋게 보는것 같지 않다.
✨ 10월 4일 (월)
📰 웹 성능을 위한 이미지 최적화
이미지 최적화를 해야하는 이유?
- 웹 페이지 바이트를 절약할 수 있다.
- 브라우저가 다운로드해야하는 바이트가 줄어든다.
- 콘텐츠를 더 빨리 다운로드하여 화면에 렌더링한다.
- 서버 저장공간이 적게 필요한다.
- 구글의 SEO 순위를 결정할 때 모바일 응답성을 고려하여, 검색순위에 노출한다.
이미지 최적화 방법론
-
이미지 폭을 조절하라.
-
페이지에서 사용하는 이미지는 보통 가로폭이 1,000px이 넘지 않는다. 블로그 처럼 좌측 우측 메뉴가 존재한다면 800px로도 충분하다.
-
최적화된 이미지 포맷을 사용하라.
-
이미지의 종류에 맞게 포맷을 설정하면 이미지 최적화를 할 수 있다. 전통적으로 많이 사용하는 JPG, PNG 포맷은 다음과 같은 이미지에서 최적화되어있다.
-
JPG: 카메라로 찍은 실제 사진 -
PNG: 만들어진 이미지 -
에 width, height 값을 선언해 Reflow를 방지하라.
-
Reflow: 를어떠한 액션이나 이벤트에 의해 DOM요소의 크기나 위치 등을 변경하면 해당 노드의 하위 노드와 상위의 노드들을 포함하여 Layout 단계를 다시 수행하게 된다. -
여러 버전의 이미지를 제공하라.
-
src 속성 : 브라우저가 srcset 과 sizes 속성을 지원하지 않으면 fall back으로 src 속성이 동작한다.
-
srcset 속성 : 이미지 파일명과 width 또는 density 설명을 쉼표로 구분한다.
-
size 속성 : size 속성은 이미지가 표시될 때의 너비를 브라우저에게 말해준다. 그러나 size 속성은 display 크기에 영향을 주지 않으며 여전히 CSS가 필요하다.
-
이미지 크기 조절 툴을 사용하라.
-
가장 많이 사용되는 이미지 크기 조절 툴은 sharp npm package 그리고 ImageMagick CLI tool이 있다.
-
Image CDNs을 사용하라.
-
Image content delivery networks(CDNs) 는 이미지 최적화에 탁월하다.
-
image CDN으로 전환하면 이미지 파일 크기를 40 ~ 80% 줄일 수 있다.
-
CSS Sprite 기법을 사용하라.
-
페이지의 첫 로딩 속도를 줄여주는 여러 방법 중에서도 서버로의 요청 횟수를 최소화 하는 것은 최적화 요소중에서도 중요하다.
-
이 중 CSS sprites는 실제 적용하기에 아주 손쉬운 방법중 하나이다.
-
lazy loading을 활용하라.
-
Lazy loading: 페이지를 로드할 때, 모든 이미지를 로드하는 것이 아니라 중요하지 않은 자원 또는 당장 필요 없는 자원의 경우 서버에 요청을 미루고 필요한 경우 해당 자원을 요청 받는 방법을 말한다. -
Lazy loading이 필요한 이유 : 데이터의 낭비를 막을 수 있다, 브라우저의 랜더링 시간을 줄여준다.
✨ 10월 5일 (화)
📰 객체지향 프로그래밍 제대로 이해하기
순차적 (비구조적) 프로그래밍
- 정의한 기능의 흐름에 따라 순서대로 동작을 추가하며 프로그램을 완성하는 방식이다.
- 흐름이 눈으로 보이기 때문에 매우 직관적이다.
- 하지만 프로그램 규모가 커지게 되면 스파게티 코드가 되기 쉽다.
- 그래서 등장한 것이 ‘절차적, 구조적 프로그래밍’이다.
절차적 (구조적) 프로그래밍
- 반복되는 동작을 함수 및 프로시저 형태로 모듈화하여 사용하는 방식이다.
프로시저: 리턴값이 없는 함수- 반복 동작을 모듈화하여 코드를 많이 줄일 수 있다. 하지만 프로시저라는 것 자체가 너무 추상적이라는 단점이 있다.
- 모듈들을 논리적으로 묶기 위한 패러다임으로 ‘객체지향 프로그래밍’ 이 등장하게 된 것이다.
객체지향 프로그래밍
- 어떤 개념에 대한 자료형과 함수를
객체형태로 함께 묶어서 관리하기 위해 ‘객체지향 프로그래밍 패러다임’이 등장하게 되었다. - 핵심 포인트는 객체 내부에 자료형 필드와 함수가 함께 존재하는 것이다.
- 객체 간의 독립성이 뚜렷하게 생기고, 중복되는 코드의 양이 줄어든다. 따라서 유지보수에 용이해질 것이다.
객체지향 프로그래밍의 4가지 특징
추상화 (Abstraction)
- 객체들이 공통적으로 필요로 하는 속성이나 동작을 하나로 추출해내는 작업이다.
- 추상적인 개념에 의존하여 설계해야 유연함을 갖출 수 있다.
캡슐화 (Encapsulation)
- 정보 은닉화를 통해 높은 응집도, 낮은 결합도를 유지할 수 있도록 설계하는 것이다.
- 한 곳에서 변화가 일어나도 다른 곳에 미치는 사이드 이펙트를 최소화 시키는 것을 의미한다.
- 결합도란 어떤 기능을 실행할 때 다른 클래스나 모듈에 얼마나 의존적인지를 나타내는 지표이다.
- 독립적으로 만들어진 객체들 간의 의존도가 최대한 낮게 만드는 것이 중요하다.
상속
- 여러 개체들이 지닌 공통된 특성을 부각시켜 하나의 개념이나 법칙으로 성립하는 과정이다.(일반화라고도 한다.)
- 상속은 자식 클래스를 외부로부터 은닉하는 캡슐화의 일종이다.
- 상속을 활용하면 상위 클래스의 구현을 활용함으로써, 코드 재사용이 용이해진다.
- 객체지향 프로그래밍에서 ‘코드 재사용’을 목적으로 하는 상속 행위는 엄격히 금한다.
- 부모 클래스의 변경이 불편해짐
- 불필요한 클래스의 증가
- 잘못된 상속 사용
다형성 (Polymorphism)
- 서로 다른 클래스의 객체가 같은 동작 수행 명령을 받았을 때, 각자의 특성에 맞는 방식으로 동작하는 것이다.
- 다형성 구현을 통해 코드를 간결하게 해주고, 유연함을 갖추게 해준다.
- 구체적으로 현재 어떤 클래스 객체가 참조되는 지는 무관하게 헐렁하게 프로그래밍하는 것이 가능하다.
✨ 10월 6일 (수)
📰 JS가 그대를 속일지라도
- 자바스크립트에서 특별히 이상한 7가지에 대해 예제 코드
[]와 ![]은 같다.
- 동등 연산자가 좌우 피연산자를 각각 숫자로 변환 한 후 비교한다.
- []와 ![] 는 각각 다른 과정을 거쳐 0으로 변환된다.
true는 ![]와 같지 않다, 그런데 이제 []와도 같지 않다
- 배열은 true와 같지 않습니다, 하지만 배열의 부정도 true와 같지 않다.
- 그런데 배열은 false와 같고 배열의 부정 역시 false와 같다.
true는 false이다
- true는 truthy 하며 1로 변환된다.
- ‘true’는 문자열이기에 NaN으로 변환된다.
- NaN은 어떤 값과 비교해도 같지 않으며, 다른 NaN과 비교해도 같지 않다.
null 과 0 비교
- 동등 연산자는 null을 0으로 변환합니다. 그렇기에 null >= 0 과 null > 0은 false가 된다.
- null은 NaN과 같이 비교시에 특별한 규칙이 있다.
- null은 null, undefined를 제외한 모든 값과 같지 않다.
3개의 수 비교
- 해당 코드는 아래의 과정으로 동작합니다
0.1 + 0.2의 결과
- 자바스크립트에서 0.3(=3/10)을 입력한다면 수는 한 번 반올림된다.
- 하지만 0.1 + 0.2를 연산하면 0.1과 0.2에서, 그리고 0.1과 0.2를 더한 값에서 반올림되기 때문에 0.1 + 0.2와 0.3은 다른 값이다.
Array.prototype.sort()의 기본 동작
- Array.prototype.sort()의 기본 동작에서는 각 값을 문자열로 변환합니다.
- 그런 다음 UTF-16 코드 유닛의 시퀀스를 비교합니다.
- javascript에서 숫자를 정렬할 때에는 아래의 방식으로 구현해야합니다.
✨ 10월 7일 (목)
📰 웹 서비스가 사용자를 판별하는 법
- Hacker News에서 전세계 Top website가 fingerprinting을 하는 지를 조사했다.
- Google, Youtube, Amazon과 같은 인기있는 웹사이트들이 WebGL fingerprinting을 하고 있다.
Fingerprinting을 하는 이유?
- 일반적으로 웹 기반 서비스를 운영한다고 할 때, 인증을 워하는 주체는 사용자이다.
- 사용자가 로그인 등을 할 때 브라우저는 쿠키 값을 저장해 stateless 하더라도 동일한 사용자인지 알 수 있다.
- 사용자가 익명화된 요청을 하면 서버는 Devixe fingerprinting을 사용한다.
WebGL Fingerprinting
- HTML5 표준에 포함된 Canvas의 WebGL 기능을 활용하는 것이다.
- Canvas에서 WebGL 기반으로 entropy가 비교적 높은 이미지를 렌더링할 때 패턴 정보들이 약간의 차이가 발생하는데 이 값을 hash값으로 뽑아낸 것이 WebGL fingerprinting이다.
✨ 10월 8일 (금)
📰 이미지 최적화의 모든 것, 최고의 완벽 가이드 - 1부
이미지 최적화가 중요한 이유
- 웹사이트 로드 시간이 100밀리 초 지연되더라도 전환율이 7% 감소할 수 있다.
- 사용자의 브라우저에서 신속한 디스플레이를 지원하기 위해 이미지를 최적화해야 한다.
- 사용자 기기가 점점 다양해지고 있습니다.그렇기 때문에 이미지를 최적화하여 모든 기기에서 원활한 환경과 일관된 수준의 성능을 제공해야 한다.
- 인터넷은 많은 에너지를 사용하므로 지구 온난화의 원인이기도 합니다. 이미지는 다운로드 시 서버 공간을 차지하고 대역폭을 증가시킨다.
- 검색 엔진은 효율적이고 민첩한 페이지를 선호한다.
웹용 이미지를 최적화하는 방법
이미지를 최적화할 때 취할 수 있는 두 가지 방법이 있다.
- 실제 이미지 크기(사이트의 이미지에 표시되는 픽셀 수) 자체를 줄일 수 있다.
- 서버에서 호스팅 되는 이미지 파일의 크기를 줄일 수 있다.
최적화된 이미지를 대상으로 할 때 알아야 할 사항
압축률(Compression rate)
- 파일을 압축한다고 해서 반드시 필요한 화질을 유지할 수 있는 것은 아니라는 점을 기억하는 것이 중요하다.
손실 vs 무손실(Lossy vs. lossless)
- 불필요한 추가 데이터가 제거되면 크기가 더 줄어들어 이미지 자체의 데이터가 손실될 수 있다.
변환 코딩(Transform coding)
- 효과적인 파일 크기 감소는 먼저 최적화를 위한 기회를 식별하는 데 달려 있다.
크로마 서브샘플링(Chroma subsampling)
- Chroma subsampling은 사람 눈의 색상 구별 기능을 기반으로 하는 또 다른 고도로 기술적인 형태의 이미지 최적화 형식이다.
허프만 코딩(Huffman coding)
- 허프만(Huffman) 코딩은 알고리즘을 사용하여 무손실 이미지 파일 크기 축소 및 최적화를 수행한다.
래스터 이미지(Raster images)
- 래스터 이미지 파일은 이미지를 비트맵 또는 전체적으로 볼 때 완전한 이미지를 만드는 작은 픽셀 격자(그리드)로 저장하고 표시한다.
벡터 이미지(Vector images)
- 벡터 이미지는 비트맵을 기반으로 하지 않고 대신 수학 공식을 사용한다.
- 이러한 공식은 다각형 또는 정의된 원곡선과 같이 명확하게 정의된 선으로 모양과 형태를 나타낸다.
- 색상 값은 균일하게 표현되며 래스터 이미지에서 볼 수 있는 픽셀 간의 변화 및 그라데이션은 찾아볼 수 없다.
✨ 10월 9일 (토)
📰 이미지 최적화의 모든 것, 최고의 완벽 가이드 - 2부
이미지 변환 및 최적화 도구(Image conversion and optimisation tools)
- 효과적인 변환을 위해 사용할 수 있는 다양한 무료 및 유료 도구가 있다.
- 일부는 콘텐츠 관리 시스템(CMS) 또는 이미징 소프트웨어와 같은 널리 사용되는 소프트웨어 플랫폼에 내장되어 있으며 다른 일부는 독립 실행형 애플리케이션이다.
온라인 이미지 최적화(Image optimisation online)
- 장접 : 높은 수준의 편의성과 직관적인 사용자 인터페이스를 제공하기 때문한다. 별도로 앱을 다운로드할 필요가 없다.
- 단점 : 앱이 비즈니스의 웹 개발 및 콘텐츠 관리 도구 키트에 추가되지 않는다. 대신 브라우저에만 존재하며 개발자가 앱에 대한 지원을 종료하기로 결정하면 솔루션을 더 이상 사용할 수 없다.
- 또한 브라우저 내 응용 프로그램에서 얻을 수 있는 압축 결과가 제한적이다.
독립형 최적화 앱(Standalone optimisation apps)
- 독립 실행형 최적화 도구 및 앱은 장치에 다운로드하는 도구이다.
- 웹 앱에 비해 기능이 뛰어나다. 압축률 및 기타 최적화 매개변수를 보다 효과적으로 제어할 수 있습니다.
이미징 소프트웨어 내에서 최적화
- 이미징 소프트웨어를 사용하는 경우 이미지 압축 및 최적화 기능을 통합하는 것이 좋다.
- 인기 있는 이미지 소프트웨어 제품군을 위한 플러그인과 애드온을 통해 이를 가능하게 하고 보다 직관적인 경험을 제공할 수 있습니다.
- 웹에 이미지를 최적화하기 위해 Photoshop을 사용하는 것이 다른 응용 프로그램과 함께 Photoshop을 사용하는 것보다 훨씬 효율적이다.
CMS 내에서 최적화
CMS: 압축률이나 이미지 품질을 손상시키지 않고 디지털 툴킷을 간소화한다.- 기업에서 웹사이트를 유지 관리하는 데 사용하는 CMS가 많이 있으며 WordPress가 가장 인기가 좋다.
대량(일괄) 최적화(Optimising in bulk)
- 대량(일괄) 최적화 도구의 정의는 일반적으로 10개 이상의 일괄 처리로 여러 이미지의 최적화를 동시에 지원하는 도구이다.
- 전체 프로세스의 효율성을 크게 높이고 번거로움과 시간을 절약할 수 있다.
대량(일괄) 이미지 크기 조정(Bulk image resizers)
- 장치에서 이미지를 선택하고 선택한 모든 파일에 크기 조정 및 최적화 매개변수를 적용한다.
- Bulk Resize Photos와 같은 도구는 한 번에 최대 150개의 이미지를 처리할 수 있으며 빠른 압축을 제공하도록 설계되었다.
- 단 60초 만에 일괄 크기 조정을 제공할 수 있다. 이 매크로 수준 변환을 통해 이미지를 대규모로 압축하여 주요 최적화 작업을 빠르고 쉽게 처리할 수 있다.
이미지 축소 도구(Image minification tools)
- 이미지 축소 기능을 사용하면 이미지가 크게 변경되지 않습니다. 대신 이미지 파일에서 불필요한 추가 코드를 제거하여 간소화된 파일을 남기므로 페이지 성능과 로딩 속도에 도움이 된다.
- 이러한 의미에서 이미지 축소는 손실이 없는 압축 형식이지만 매우 큰 이미지에는 적합하지 않을 수 있다.
✨ 10월 10일 (일)
📰 Mistakes | 주니어 리액트 개발자인 내가 실수하고 있었던 것
이전 상태를 기반으로 새로운 상태를 세팅하기
- React에서 setState는 state 값을 변경할 때 사용하는 함수다.
- setState는 첫 번째 인자를 object나 function으로 받을 수 있다. object가 인자일 경우 state = object로 업데이트 된다.
- 하지만 이전의 상태를 기반으로 연속적으로 업데이트 해야할 때에는 (eg. 새로운 상태 = 이전 상태 + 1, setState(!isState)) setState가 비동기적으로 작동하기 때문에 안전하지 않다.
- setState의 인자로 콜백을 넣어준다면, 콜스택에 쌓이며 호출된 순서대로 작동하고 최신 상태를 기반으로 실행되기 때문에 안전하게 state를 변경할 수 있습니다.
state 얕은 복사
- 리액트에선 state의 불변성을 지켜주고 setState 함수를 통해 상태 업데이트를 해주어야 한다.
- 만약 state의 불변성을 지켜주지 않는다면 컴포넌트 렌더링이 무분별하게 일어날지도 모르고, 컴포넌트를 최적화하기 어려워진다.
- 참조 데이터 안에 또 다른 참조 데이터가 있을 땐, 그 분기점마다 스프레드 연산자를 사용해야 한다.
- 혹은 데이터 구조가 좀 더 복잡해진다면 Immer.js의 produce 함수를 사용해서 상태의 불변성을 지키며 업데이트할 수도 있다.
Nullish Coalescing(??)과 OR operator(||)
- value가 undefined나 null인 경우를 알기 위해 OR operator를 많이 쓴다.
- OR operator는 좌측이 false인 경우, 우측의 값을 리턴합니다.
- 그런데 0 또한 false이고 ” 또한 false입니다. 따라서 값에 0이나 ”가 들어올 수도 있는 경우 OR operator와 Nullish Coalescing를 구분해서 사용해야 한다.
- 이처럼 Nullish coalescing operator(??)는 좌측이 undefined인 경우에만 우측의 값을 리턴하고, 그 외의 경우에는 그대로 리턴한다.
JSON mock data 만들기
- JSON Mock data를 만들 때, JSON.stringify()를 사용하면 된다.
컴포넌트에 boolean props true 표시 X, string props 브라켓 X
- 컴포넌트에 전달하는 boolean props가 true일 때에는 따로 true를 표시하지 않는다.
- string props는 컬리 브라켓을 쓸 필요 없이 double quote로만 전달한다.
여러 API 동시에 완료시키기
- 한 개의 컴포넌트 안에서 여러개의 API를 연결해야 하는 상황이라면 첫 번째의 response와 마지막 열두 번째의 response까지 텀이 발생해서 순차적으로 view가 뜨는 문제가 발생할 수 있다.
- 이를 해결하는 방법은 Promise.all과 Promise.allSettled을 사용하는 것이다.
- Promise.all은 중간에 하나의 request가 rejected 되면 모든 request의 실행이 중단되고 다음의 request는 실행된다.
- Promise.allSettled는 하나가 rejected 되더라도 모든 request가 실행되고 결과를 return한다.
✨ 10월 11일 (월)
📰 알고리즘의 시간 복잡도와 Big-O 쉽게 이해하기
알고리즘이란?
-
어떤 목적을 달성하거나 결과물을 만들어내기 위해 거쳐야 하는 일련의 과정들을 의미한다.
-
여러가지 상황에 따른 알고리즘은 모두 다르다. 따라서 시간복잡도가 가장 낮은 알고리즘을 선택하여 사용한다.
-
알고리즘의 실행시간은 컴퓨터가 알고리즘 코드를 실행하는 속도에 의존한다.
-
이 속도는 컴퓨터의 처리속도, 사용된 언어종류, 컴파일러의 속도에 달려있다.
점금적 표기법(Asymptotic notation)
-
점금적 표기법: 중요하지 않는 상수와 계수들을 제거하고 알고리즘의 실행시간에서 중요한 성장률에 집중하는 방식이다. -
성장률: 입력값의 크기에 따른 함수의 증가량 -
최상의 경우 : 오메가 표기법 (Big-Ω Notation)
-
평균의 경우 : 세타 표기법 (Big-θ Notation)
-
최악의 경우 : 빅오 표기법 (Big-O Notation)
-
평균인 세타 표기를 하면 가장 정확하고 좋겠지만 평가하기가 까다롭다.
-
그래서 최악의 경우인 빅오를 사용하는데 알고리즘이 최악일때의 경우를 판단하면 평균과 가까운 성능으로 예측하기 쉽기 때문이다.
빅오 표기법(Big-O)
- 빅오 표기법은 불필요한 연산을 제거하여 알고리즘분석을 쉽게 할 목적으로 사용된다.
- Big-O로 측정되는 복잡성에는 시간과 공간복잡도가 있다.
시간복잡도: 입력된 N의 크기에 따라 실행되는 조작의 수를 나타낸다.공간복잡도: 알고리즘이 실행될때 사용하는 메모리의 양을 나타낸다. 요즘에는 데이터를 저장할 수 있는 메모리의 발전으로 중요도가 낮아졌다.

시간복잡도
-
시간복잡도에서 중요하게 보는것은 가장큰 영향을 미치는 $n$ 의 단위이다.
-
$O(1)$ –> 상수
-
$O(n)$ –> n이 가장 큰영향을 미친다.
-
$O(n^2)$ –> $n^2$ 이 가장 큰영향을 미친다.
-
하나의 루프를 사용하여 단일 요소 집합을 반복 하는 경우 : $O(n)$
-
컬렉션의 절반 이상 을 반복 하는 경우 : $O(n/2)$ -> $O(n)$
-
두 개의 다른 루프를 사용하여 두 개의 개별 콜렉션을 반복 할 경우 : $O(n + m)$ -> $O(n)$
-
두 개의 중첩 루프를 사용하여 단일 컬렉션을 반복하는 경우 : $O(n^2)$
-
두 개의 중첩 루프를 사용하여 두 개의 다른 콜렉션을 반복 할 경우 : $O(n * m)$ -> $O(n^2)$
-
컬렉션 정렬을 사용하는 경우 : $O(n*log(n))$

✨ 10월 12일 (화)
📰 SOLID 원칙, 어렵지 않다!
객체지향 설계과정
- 요구사항(제공해야 할 기능)을 찾고 세분화 한다. 그리고 그 기능을 알맞은 객체로 할당한다.
- 기능을 구현하는 데에 필요한 데이터를 객체에 추가한다.
- 해당 데이터를 이용하는 기능을 구현한다. (기능은 최대한 캡슐화)
- 객체 간에 어떻게 메소드 호출을 주고받을 지 결정한다.
객체지향 설계원칙
SRP (Single Responsibility) 단일 책임 원칙
- 클래스는 단 한개의 책임을 가져야 한다.
- 클래스를 변경하는 이유는 단 하나여야 한다.
- 이를 지키지 않으면, 한 책임의 변경에 의해 다른 책임과 관련된 코드에 영향을 미칠 수 있다.
- 이렇게 되면 유지보수가 매우 비효율적이다.
OCP (Open-Closed) 개방-폐쇄 원칙
- 확장에는 열려있어야 하고, 변경에는 닫혀 있어야 한다.
- 즉, 기존의 코드를 변경하지 않고 기능을 수정하거나 추가할 수 있도록 설계해야 한다.
- 이를 지키지 않으면 instanceof 와 같은 연산자를 사용하거나, 다운 캐스팅 발생한다.
LSP (Liskov Substitution) 리스코프 치환 원칙
- 하위 타입 객체는 상위 타입 객체에서 가능한 행위를 수행할 수 있어야 한다.
- 즉, 상위 타입 객체를 하위 타입 객체로 치환해도 정상적으로 동작해야 한다.
- 상속관계에서는 꼭 일반화 관계 (IS-A) 가 성립해야 한다. (일관성 있는 관계인지)
- 상속관계가 아닌 클래스들을 상속관계로 설정하면, 이 원칙이 위배된다. (재사용 목적으로 사용하는 경우)
ISP (Interface Segregation) 인터페이스 분리 원칙
- 클라이언트는 자신이 사용하는 메소드에만 의존해야 한다는 원칙을 가진다.
- 한 클래스는 자신이 사용하지 않는 인터페이스는 구현하지 않아야 한다.
- 하나의 통상적인 인터페이스보다는 차라리 여러 개의 세부적인 (구체적인) 인터페이스가 나온다.
- 인터페이스는 해당 인터페이스를 사용하는 클라이언트를 기준으로 잘게 분리되어야 한다.
DIP (Dependency Inversion) 의존 역전 원칙
- 의존 관계를 맺을 때, 변하기 쉬운 것 (구체적인 것) 보다는 변하기 어려운 것 (추상적인 것)에 의존해야 한다.
- 구체화된 클래스에 의존하기 보다는 추상 클래스나 인터페이스에 의존한다.
- 즉, 고수준 모듈은 저수준 모듈의 구현에 의존해서는 안 된다.
- 저수준 모듈이 고수준 모듈에서 정의한 추상 타입에 의존해야 한다.
- 저수준 모듈이 변경되어도 고수준 모듈은 변경이 필요없는 형태가 이상적이다.
✨ 10월 13일 (수))
📰 검색 상단에 오르기 위한 SEO 최적화
- 구글 서치엔진을 기준으로 검색 우선순위를 높일 수 있는 쉽고 대표적인 방법에 대한 소개 글이다.
Lighthouse
- 먼저 크롬 개발자도구의 Lighthouse의 SEO점수를 통해 페이지의 검색 우선순위를 쉽게 파악할 수 있다.
- SEO점수는 페이지의 속도, 접근성, 구조 등으로 정해지게 되는데, Lighthouse는 취약점에 대해 보완할 수 있는 방법까지 제시해주고 있다.
도메인
- 복잡하고 읽기 어려운 도메인과 읽기 쉬운 도메인은 서치엔진이 크게 구별하지 못한다.
- 국내 도메인(kr)보다는 국제 도메인(com)이 검색 우선순위에 유리하며, 신생 도메인보다 오래된 도메인이 비교적 검색 우선순위에 우선순위를 갖는다.
HTML 최적화
- 키워드마스터, KWfinder 등의 페이지는 특정 검색어의 검색량을 확인하여 경쟁력 있는 타이틀 설정을 도와준다.
lang
- 주로 보여져야 하는 국가의 국가코드를 이용하는 것이 좋다.
Description
- Description은 페이지에 대한 설명으로 페이지를 공유할 때나 검색창 등에서 페이지에 대한 설명을 나타내준다.
- 단일 Description을 여러 페이지에 사용하는 것보다 각 페이지별로 Description을 사용하는 것이 검색엔진 최적화에 유리하다.
태그 최적화
- Html 태그의 h1, h2 같은 경우는 순서대로 높은 검색 우선도를 가지고 있다.
- strong태그와 em는 같은 역할을 하는 b, i 태그와 달리 강조의 효과를 가지고 있기 때문에 검색순위에 우선순위를 갖는다.
- 이미지의 alt태그와 title태그 유무도 검색최적화에 영향을 미친다.
- 불필요한 의미의 이미지라면 차라리 alt태그를 작성하지 않는 것이 좋다.
웹사이트 구조 최적화
- 잘 짜여진 웹사이트 구조는 검색엔진의 높은 점수를 받는다.
- 중요하거나 먼저 읽어야 하는 것들은 좌측상단에서 우측하단 순으로 배치하는것이 좋습니다.
✨ 10월 14일 (목)
📰 Preload의 개념, 그리고 올바른 사용법
Preload란?
- 필요한 리소스 자원을 서버에 요청할 때 여러 자원을 동시에 요청하게 되고 서버에서는 요청 순서에 상관없이 준비가 되는대로 응답을 하게 된다. 이때, 특정 리소스를 빠르게 로딩하도록 우선순위를 부여하는 방법이 바로 Pre Load를 지정하는 방식이다.
- Head 태그에 빠르게 로딩시킬 파일을 Pre Load로 지정하게 되면, 페이지 요청 시 해당 소스 자원을 우선적으로 로드를 수행하게 된다.
불필요한 리소스에 PreLoad는 걸지 않기
- 우선 PreLoad로 선언되는 순간, 해당 소스가 실제로 사용하든 하지 않든 무조건 서버로부터 요청하여 다운로드를 하게 된다.
- 초기 로딩 성능을 저하시키는 역효과를 발생시킬 수 있으므로, 초기 로드 시 사용되지 않는 리소스에 PreLoad를 설정하지 않게 주의해야 한다.
✨ 10월 15일 (금)
📰 [2021.06.11] Production Environment에서 SourceMap 보안 이슈 해결
문제
- Production 환경에 소스코드를 배포할 때, Webpack Build를 통해 기존 코드를 Uglify하게 만들어 업로드를 한다.
- 그러나 Source Map 파일이 Production 환경에 같이 올라가면, Source Map 파일을 통해 Uglify JS 파일들이 기존에 어떻게 작성되어있는지 트래킹이 가능하게 되어버리는 보안 이슈가 발생한다.
Next.js 환경에서 Production Build 시 Source Map을 생성해야 했던 이유
- 유저 환경에서 Error가 발생 시, Sentry를 통해 어떤 부분에서 에러가 발생했는지 확인이 가능해야 했다. - Sentry 환경에 Source Map을 업로드 하기 위해 SentryWebpackPlugin을 사용하여 Source Map을 임의로 생성하도록 해야만 했다.
해결
- Build된 파일의 디렉토리 내에 확장자 ‘.map’ 파일을 모두 찾아서 지우도록 하는 Script 명령어를 추가한다.
- 그리고 dockerFile에서 Build가 끝나면 해당 명령어를 실행하도록 했다.
✨ 10월 16일 (토)
📰 [Browser] Reflow와 Repaint
Repaint(Redraw)란?
- Repaint는 화면에 변화가 있을 때 화면을 그리는 과정이다.
- 화면의 구조가 변경되었을 때에는 Reflow 과정을 거쳐 화면 구조를 다시 계산한 후 Repaint 과정을 통해 화면을 다시 그린다. 즉 화면의 구조가 변경되었을 때에는 Reflow와 Repaint 모두 발생한다.
- 화면의 구조가 변경되지 않는 화면 변화의 경우 Repaint만 발생한다.
Reflow(Layout)란?
Reflow는 화면 구조(Layout)이 변경되었을 때, 뷰포트 내에서 렌더 트리의 노드의 정확한 위치와 크기를 계산하는 과정을 Reflow(혹은 Layout)이라고 한다.
Reflow가 발생하는 경우
- DOM 노드의 추가, 제거
- DOM 노드의 위치 변경
- DOM 노드의 크기 변경(margin, padding, border, width, height 등..)
- CSS3 애니메이션과 트랜지션
- 폰트 변경, 텍스트 내용 변경
- 이미지 크기 변경
- offset, scrollTop, scrollLeft과 같은 계산된 스타일 정보 요청
- 페이지 초기 렌더링
- 윈도우 리사이징
Reflow 최적화
- 스타일을 변경할 경우 가장 하위 노드의 클래스를 변경한다.
- 인라인 스타일을 사용하지 않는다.
- 애니메이션이 있는 노드는 position을 fixed 또는 absolute로 지정한다.
- 퀄리티, 퍼포먼스의 타협점을 찾는다.
- table 레이아웃을 피한다.
- IE의 CSS 표현식을 사용하지 않는다.
- CSS 하위 선택자를 최소화한다.
- 숨겨진 노드의 스타일을 변경한다.
- 클래스를 혹은 cssText 사용하여 한 번에 스타일을 변경한다.
- DOM 사용을 최소화한다.
- 캐시를 활용한다.
✨ 10월 17일 (일)
📰 HTTP vs HTTPS
HTTP란?
- HTTP는 Hyper Text Transfer Protocol의 줄임말으로써 서버와 클라이언트간에 데이터를 주고 받는 프로토콜이다.
- HTTP는 텍스트, 이미지,영상, JSON 등등 거의 모든 형태의 데이터를 전송할수 있다.
HTTP는 보안적으로 안전한가?
- HTTP 통신은 클라이언트와 서버간의 통신에 있어서 별다른 보안 조치가 없기때문에 만약 누군가 네트워크 신호를 가로챈다면 HTTP의 내용은 그대로 외부에 노출된다.
HTTPS?
- 기존의 HTTP 프로토콜은 전송계층의 TCP위에서 동작한다.
- SSL(Secure Sockets Layer)이라는 보안계층이 전송계층 위에 올라간다.
- HTTPS는 SSL 위에 HTTP를 얹어서 보안이 보장된 통신을 하는 프로토콜이다.
- SSL 암호화 통신은 공개키 암호화 방식이라는 알고리즘을 통해 구현된다.
공개키 암호화 방식이란?

- 공개키 암호화 방식에는 공개키와 개인키 두 종류의 키가 존재한다.
- 한쪽 키로 데이터를 암호화 했다면 오직 다른쪽 키로만 복호화를 할 수 있다.
✨ 10월 18일 (월)
📰 물 흐르듯 읽어보는 TCP/IP
회선 교환 (Circuit Switching) 방식
- 패킷 통신이 등장하기 전 통신방법이다.
- 통신하고자 하는 두 호스트가 데이터를 전송하기 전에 미리 데이터 이동 경로를 하나 설정해두는 방식이다.
- 회선의 트래픽이나 이동 효율을 전혀 고려하지 않은 채 미리 정하는 방식이다.
- 이미 설정된 이동 경로는 할당 해제될 때까지 다른 호스트들이 사용할 수 없게 된다.
- 단절에 매우 취약하다.
패킷 교환 (Packet Switching) 방식
- 미리 이동 경로를 정하지 않고, 데이터를 패킷 (Packet) 이라는 작은 단위로 나누어 다중 노드로 구성된 네트워크를 통해 전송하는 개념이다.
- 전송될 데이터는 네트워크를 통해 전송되기 전에 패킷으로 쪼개어지고, 각 패킷에는 고유 번호가 지정되어 있어서 네트워크를 거쳐 최종 수신지에 도착했을 때에 번호 순서대로 결합되어 원래 데이터로 완성되는 방식이다.
- 패킷은 전송 당시 가장 효율적인 경로를 설정하여 최종 목적지까지 이동하게 된다.
TCP/IP
- TCP 프로토콜은 신뢰성 있고 무결성을 보장하는 연결을 통해 데이터를 안전하게 전달해주는 전송 프로토콜이다.
- IP 프로토콜은 패킷들을 가장 효율적인 방법으로 최종 목적지로 전송하기 위해 필요한 프로토콜이다.
- TCP/IP 가 제시하는대로 데이터를 캡슐화한다.
TCP/IP 4계층
- 4계층 : 응용 계층 (Application)
- 3계층 : 전송 계층 (Transport)
- 2계층 : 인터넷 계층 (Internet)
- 1계층 : 네트워크 인터페이스 계층 (Network Interface)
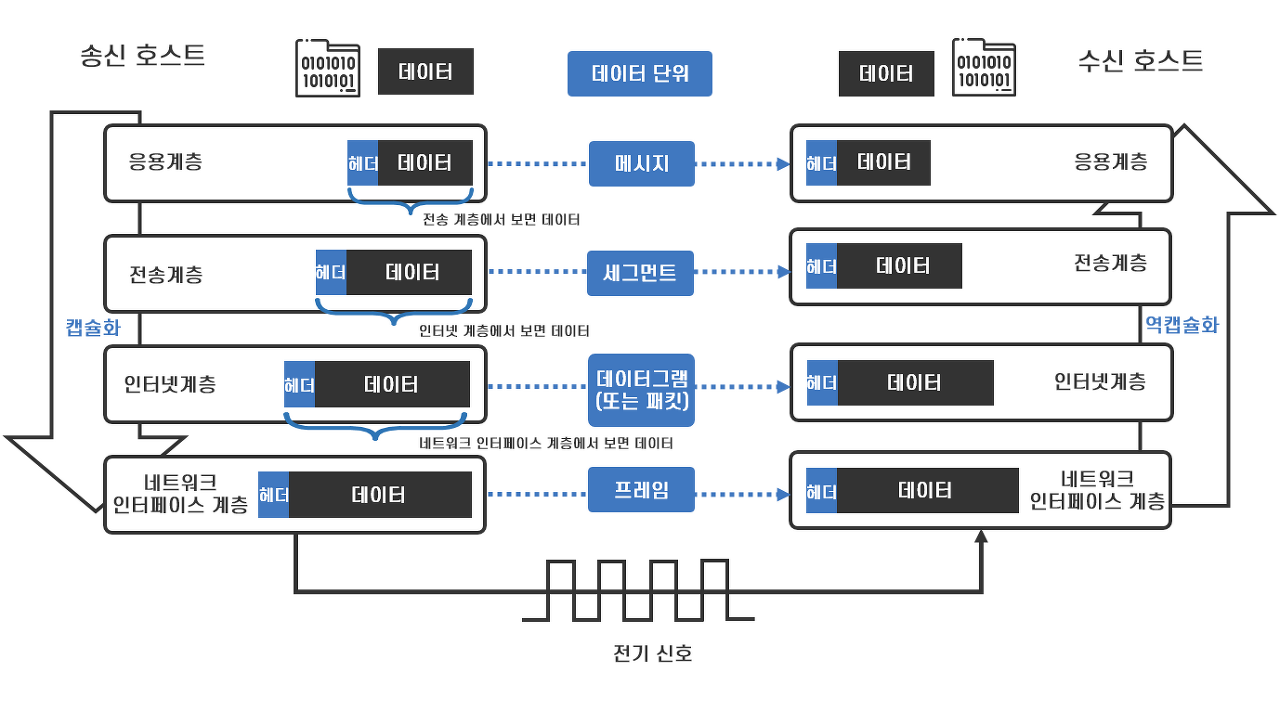
- 송신 호스트에서 데이터를 보내기 위해서는 4계층으로부터 1계층 까지 순차적으로 거쳐가며 데이터를 캡슐화해야 한다.
- 수신 호스트에서 이를 수신받아 1계층부터 4계층까지 순차적으로 거쳐가며 데이터를 역캡슐화해가며 최상 계층인 응용 계층에서 데이터를 수신받아 적절히 활용하게 된다.
✨ 10월 19일 (화)
📰 만남과 이별에는 항상 “악수”가 따른다

3-way Handshake
-
TCP의 연결 성립 과정을 칭하는 용어이다.
-
클라이언트가 서버에게 SYN 패킷 전송
-
서버가 SYN(X) 를 수신하고, 클라이언트에게 SYN 을 잘 받았다는 의미로 ACK 과 SYN 패킷 전송
-
클라이언트는 서버로부터 온 ACK(X + 1)과 SYN(Y) 패킷을 수신하고, ACK(Y + 1)을 서버로 전송
4-way Handshake
-
TCP의 연결 해제 과정을 칭하는 용어이다.
-
클라이언트는 서버에게 ‘저 이제 끊을게요’ 하는 의미로 FIN 플래그를 전송
-
서버는 FIN 을 수신하고, ‘알겠어용’ 하는 의미로 클라이언트에게 ACK 으로 답장
→ 남은 데이터를 마저 보내기 위해 CLOST_WAIT 상태로 전환
- 이후 데이터를 모두 보냈다면, 연결이 종료됐다는 FIN 플래그를 클라이언트에게 전송
- 클라이언트는 해당 FIN 을 수신하고 확인했다는 의미로 ACK 을 서버로 전송
→ 혹시나 아직 안 온 데이터가 있을 수 있기 때문에 이를 대기하기 위해 TIME_WAIT 상태로 전환
- 서버가 클라이언트로부터 ACK 을 수신했다면, 소켓을 닫게 된다. 그리고 TIME_WAIT 시간이 끝나면 클라이언트도 소켓을 닫게 된다. 이로써 통신이 완벽히 해제된다.
✨ 10월 20일 (수)
📰 2021 백엔드 개발자 로드맵
- roadmap.sh의 2021 버전 백엔드 개발자 로드맵을 번역, 관련 내용을 링크를 통해 정리했다.
- 수시로 방문하면서 해당 내용을 학습해야겠다.
✨ 10월 21일 (목)
📰 내가 개발자가 될 상인가 (네이버 FE 1년차 후기)
개발자는 개발(만)을 한다
- 새로운 기능이나 디자인에 대한 의견을 낼 여유가 거의 없다.
- 프로젝트 진행중에는 개발 측면에서도 새로운 시도를 도전하기 쉽지 않다.
성실함이 중요한 이유
- 개발자란 직종이 어느정도는 개개인의 역량을 신뢰하며 일을 맡기는 경향이 있기 때문에 그 개인이 일을 게을리 하기 시작하면 걸러내는 게 쉽지 않다.
- 기획에 맞춰 페이지를 구현하는 데는 다양한 팀과의 소통이 필요하다.
- 내가 게으름을 부리면 이 모든 사람들과의 소통이 뒤쪽으로 압축되어 밀리게 되어 다같이 불행해지는 상황과 맞닥뜨리게 된다.
✨ 10월 22일 (금)
📰 HTTP의 특성과 쿠키, 세션, 토큰
HTTP의 특성
Connectionless
- HTTP는 통신을 한번 할 때 클라이언트와 서버를 연결하고, 통신이 끝나면 바로 연결을 끊는다.
- 이를 통해 서버 자원을 효율적으로 관리하고 여러 클라이언트의 요청에 대응한다.
- HTTP 1.1부터 일정 시간동안 계속 요청을 보내면 한번의 커넥션 연결로 처리하며 이를 지속 커넥션이라 한다.
Stateless
- HTTP는 이전 요청의 상태를 기록하지 않기 때문에 서버는 클라이언트를 식별할 수 없다.
- 이전 요청이 어떻게 끝났느냐에 따라 다음 요청이 영향을 받지 않고 모든 요청이 독립적이다.
웹의 개인화
- 웹이 발전함에 따라 각 클라이언트에 맞게 개인화된 웹 사이트를 제공하고자 하는 욕구가 발생했다.
- 개인화를 위해서 여러 클라이언트들을 서버가 식별할 수 있어야 했다.
Cookie
UNIX OS에서 프로그램 사이에 전송되는 작은 데이터 패킷을 “Magic Cookie”라고 불렀는데, 클라이언트에서 서버로 전송되는 작은 데이터라는 개념이 비슷하여 여기서 가져온 것이라 한다.
HTTP 쿠키는 서버가 클라이언트에게 준 정보를 브라우저에 저장하고, 클라이언트가 요청을 보낼 때 HTTP 헤더에 정보를 담아서 서버에 전달한다.

쿠키 제약조건
- 브라우저는 총 300개의 쿠키를 저장할 수 있다.
- 하나의 도메인당 20개의 쿠키를 가질 수 있다. 초과되면 가장 적게 사용된 것부터 삭제한다.
- 하나의 쿠키는 4KB까지 용량을 차지할 수 있다.
쿠키의 한계
- 민감한 정보를 그대로 HTTP 통신에 노출하는 경우 탈취당할 수 있다. 아이디와 패스워드를 쿠키에 넣어서 모든 요청마다 인증 정보를 포함하게 할 수 있는데, 통신 과정에서 패킷을 가로채가면 패스워드가 유출될 수 있다.
- 쿠키의 보안 취약점을 보완하기 위해 “세션”이 등장한다.
Session
쿠키가 탈취당할 수 있다는 것을 인지하여, 민감한 정보는 서버에만 저장하고 쿠키에는 서버에 저장된 정보를 찾을 수 있는 키만 전달하는 방식이다.
세션의 한계
- 쿠키에 담긴 정보가 있는 그대로는 의미 없지만, 탈취한 쿠키를 이용해 서버에 요청을 보내면 정보가 유출될 수 있다.
- 서버에 정보를 저장해야 하기 때문에 메모리 공간을 차지한다.
- 쿠키로부터 받은 세션 ID로 세션 스토리지를 탐색해야 하는 시간이 든다.
- 동시 접속자가 많은 서비스의 경우 서버 과부하의 원인이 되어, 서버에 정보를 저장하지 않는 “토큰”이 등장한다.
Token
- 서버는 인증에 필요한 정보들을 암호화시켜 토큰을 발행하고, 클라이언트는 발행받은 토큰을 HTTP 헤더에 계속 넣어서 요청을 보내는 방식이다.

토큰의 한계
- 이미 발급된 토큰은 유효기간이 만료되기 전까지 계속 사용할 수 있기 때문에, 악의적으로 이용될 수 있다. 따라서 토큰 유효기간을 짧게 하고 Refresh Token을 새로 발급해야 한다.
- 토큰의 길이가 쿠키, 세션에 비해 길어서 인증이 필요한 요청이 많을 때 서버 자원낭비가 발생한다.
✨ 10월 23일 (토)
📰 [IT 기술] 인터넷의 작동원리
1. 인터넷이란?
- 인터넷이란 각 컴퓨터들간의 TCP/IP 통신 프로토콜을 이용해서 서로 데이터를 주고 받도록한 네트워크를 말한다.
TCP/IP란?
- TCP/IP가 나타난 이유는 컴퓨터간의 통신을 위해서다.
- TCP/IP는 컴퓨터와 컴퓨터간의 지역네트워크(LAN), 광역네트워크(WAN)에서 원할한 통신을 가능하도록 하기위한 통신규약으로 정의할 수 있다.
IP : 네트워크 상에서 컴퓨터는 고유한 주소가 있다. 컴퓨터의 주소는 인터넷에 접속할때 컴퓨터 각각에 부여받는다. 이 주소는 총 4바이트로 이루어져있다.
TCP : 클라이언트와 서버간에 데이터를 신뢰성있게 전달하기 위해 만들어진 프로토콜이다. 그리고 TCP는 근거리 통신망(LAN), 원거리 통신망(WAN), 인트라넷, 인터넷 등 컴퓨터에서 실행되는 프로그램 간에 일련의 데이터를 안정적으로 순서대로 에러없이 데이터를 교환할 수 있게 해준다.
2. 네트워크

- 두개의 컴퓨터가 통신이 필요할때 다른 사람의 컴퓨터와 물리적(케이블 선) 또는 무선(WiFi, Bluetooth)으로 연결이 되어야한다.
- 만약 여러 대의 컴퓨터를 이런 방식으로 연결하게 되면 아래와 같다.

- 이렇게 연결이 되어있으면 몇십대가 관리하기도 힘들뿐더러 가독성도 떨어진다.
- 이 문제를 해결하기 위해 라우터가 나왔다. 아래의 그름은 각 컴퓨터를 라우터라는 특수한 소형컴퓨터에 연결하였다.

- 하지만 이 방법도 몇백 몇천대의 컴퓨터는 단일 라우터로 확장이 불가능하다.
- 라우터도 컴퓨터이기 때문에 라우터끼리 연결해서 네트워크를 확장할 수 있다.

- 아주 먼곳에 있는 지역과는 케이블 연결이 불가능하다.
- 하지만 이미 전력 및 전화와 같이 집에 연결된 케이블이 있다.
- 네트워크를 전화 시설과 연결하기 위해 모뎀이라는 특별한 장비가 필요하다.
- 모뎀은 네트워크의 정보를 전화 시설에서 처리 할 수 있는 정보로 바꾸며 그 반대의 경우도 마찬가지입니다.

요약
- 컴퓨터와 컴퓨터를 케이블 또는 무선 연결
- 개수가 많아지면 복잡하여 라우터 등장
- 단일 라우터로만으로도 몇백, 몇천대 연결은 불가능하여 라우터와 라우터를 연결
- 거리가 먼 지역은 케이블과 무선으로 연결이 불가능, 그래서 내트워크의 정보를 전화 시설에 처리 할 수있는 모뎀이 나옴
- 네트워크에서 도달하려는 네트워크로 데이터를 보내기위해 ISP에 연결
✨ 10월 24일 (일)
📰 HTTP란 무엇인가?
HTTP (HyperText Transfer Protocol)
- 텍스트 기반의 통신 규약으로 인터넷에서 데이터를 주고받을 수 있는 프로토콜이다.
- 규약을 정해두었기 때문에 모든 프로그램이 이 규약에 맞춰 개발해서 서로 정보를 교환할 수 있게 되었다.
HTTP 동작
클라이언트 즉, 사용자가 브라우저를 통해서 어떠한 서비스를 url을 통하거나 다른 것을 통해서 요청(request)을 하면 서버에서는 해당 요청사항에 맞는 결과를 찾아서 사용자에게 응답(response)하는 형태로 동작한다.
요청 : client -> server
응답 : server -> client
HTTP 특징
- HTTP 메시지는 HTTP 서버와 HTTP 클라이언트에 의해 해석이 된다.
- TCP/ IP를 이용하는 응용 프로토콜이다.
- HTTP는 연결 상태를 유지하지 않는 비연결성 프로토콜이다.
- HTTP는 연결을 유지하지 않는 프로토콜이기 때문에 요청/응답 방식으로 동작한다.
Request (요청)
클라이언트가 서버에게 연락하는 것을 요청이라고 하며 요청을 보낼때는 요청에 대한 정보를 담아 서버로 보낸다.
Request Method (요청의 종류)
- GET : 자료를 요청할 때 사용
- POST : 자료의 생성을 요청할 때 사용
- PUT : 자료의 수정을 요청할 때 사용
- DELETE : 자료의 삭제를 요청할 때 사용
1. 시작줄 (첫 줄)
첫 줄은 시작줄로 메서드 구조 버전으로 구성되었다.
- GET : HTTP Method
- https://velog.io/@surim014 : 사이트 주소
- HTTP/1.1 : HTTP 버전
2. 헤더 (두 번째 줄부터)
두번째 줄부터는 헤더이며 요청에 대한 정보를 담고 있다. User-Agent, Upgrade-Insecure-Requests 등등이 헤더에 해당되며 헤더의 종류는 매우 많다.
3. 본문 (헤더에서 한 줄 띄고)
본문은 요청을 할 때 함께 보낼 데이터를 담는 부분이다. 현재 예시에는 단순히 주소로만 요청을 보내고 있고 따로 데이터를 담아 보내지 않기 때문에 본문이 비어있다.
Response (응답)
서버가 요청에 대한 답변을 클라이언트에게 보내는 것을 응답이라고 한다.
Status Code (상태 코드)
상태 코드에는 굉장히 많은 종류가 있다. 모두 숫자 세 자리로 이루어져 있으며, 아래와 같이 크게 다섯 부류로 나눌 수 있다.
- 1XX (조건부 응답) : 요청을 받았으며 작업을 계속한다.
- 2XX (성공) : 클라이언트가 요청한 동작을 수신하여 이해했고 승낙했으며 성공적으로 처리했음을 가리킨다.
- 3XX (리다이렉션 완료) : 클라이언트는 요청을 마치기 위해 추가 동작을 취해야 한다.
- 4XX (요청 오류) : 클라이언트에 오류가 있음을 나타낸다.
- 5XX (서버 오류) : 서버가 유효한 요청을 명백하게 수행하지 못했음을 나타낸다.
1. 시작줄 (첫 줄)
첫 줄은 버전 상태코드 상태메시지로 구성되어 있다.
2. 헤더 (두 번째 줄부터)
두 번째 줄부터는 헤더로 응답에 대한 정보를 담고 있다.
3. 본문 (헤더 뒤부터)
응답에는 대부분의 경우 본문이 있다. 보통 데이터를 요청하고 응답 메시지에는 요청한 데이터를 담아서 보내주기 때문이다. 응답 메시지에 HTML이 담겨 있는데 이 HTML을 받아 브라우저가 화면에 렌더링한다.
✨ 10월 25일 (월)
📰 CSS-in-JS, 무엇이 다른가요?
CSS in JS?

- CSS-in-JS는 단어 그대로 JavaScript코드에서 CSS를 작성하는 방식을 말합니다.
1st Generation
*.(module).css으로 파일을 생성하고 CSS pre-processor를 사용하여css module형태로 사용하였다.- ‘runtime에서의 동작’이 없기 때문에 zero runtime css-in-js 의 특징을 갖는다.
2nd Generation
- JS변수를 활용하여 CSS를 작성할 수 있는 Radium과 같은 라이브러리가 등장한다.
- 컴포넌트에서 스타일을 제어할 수 있는 형태였지만, inline style을 사용하므로
:before,:nth-child등의 pseudo selector를 사용할 수 없는 등 CSS의 모든 spec을 사용할 수 없다.
3rd Generation
- 2세대에서 inline-style방식을 선택하며 마주한 ‘사용할 수 있는 css syntax 제한’에 대한 한계를 극복하기 위해 aphrodite, glamor등의 라이브러리에서는 다른 방식으로 스타일을 생성한다.
- JavaScript 템플릿으로 CSS를 작성하면 빌드 과정에서
<style>태그를 생성하여 주입한다. - pseudo element, media query 등 부족했던 CSS Spec을 지원하기 시작했으나, 동적으로 변경되는 스타일은 정의하기 까다로웠다.
4th Generation
- 4세대에서는 3세대의 한계인 ‘JavaScript 코드로 제어하는 동적인 스타일링’을 runtime 개념을 도입하여 해결했다.
- prop가 변할 때마다 스타일을 동적으로 생성하여 JavaScript 코드로 동적인 스타일링이 가능하다.
- runtime에서 스타일을 생성하는 방식은 대부분 문제 없으나 스타일 계산 비용이 커서 스타일이 복잡한 컴포넌트에서 차이가 발생한다.
Critical CSS
- 현재 화면에서 필요한 CSS만 효율적으로 먼저 로딩하는 방법이다.
styled-components
- 현재 페이지에서 사용되는 스타일만 별도의 스타일 시트로 생성한다.
- 최초 렌더링 이후 props/state에 의해 변경되는 스타일은 style tag에 동적으로 삽입한다.
emotion
- styled-components와 비슷하게 초기 페이지 렌더링에 필요한 critical css를 추출, 이후 동적 스타일은 runtime에 생성한다.
linaria
- 빌드시 critical css 추출한다.
Performance
- runtime이 반드시 성능 저하를 초래하는 것은 아니다.
runtime css-in-js
- css를 parsing하는데 blocking 되는 시간을 줄이는 노력이 필요하다.
- DOM 트리는 두고 CSSOM만 수정하는 방식으로 해결했다.
- 단 development mode에서는 DOM을 수정한다.
zero runtime css-in-js
-
병목을 일으키는 부분에 부분적으로 zero-runtime을 도입한다.
-
styled-components와 linaria의 퍼포먼스 비교는 linaria가 우세하지만 도구의 한계가 명확해서 신중히 고려해야한다.
stitches (near-zero runtime)
- styled-components와 유사한 api를 표방하지만 runtime 대신 near-zero runtime을 표방한다.
- component prop에 의한 interpolation을 최소화하는 방향의 API 제공한다.
- styled-components에서는 prop에 의한 완전 동적 스타일링이 가능하지만, stitches는 사전에 정의한 variants에 의한 스타일링만 가능하다.
css-in-js 외의 방법
- Atomic CSS
- tailwindcss
- tailwind + twin.macro
- stiches.js
✨ 10월 26일 (화)
📰 프론트엔드 개발, 뭐하는 직종이야?
프론트엔드 개발, 뭐하는 직종이야?
백엔드(Back-End) API (Application Programming Interface)에서 가져온 데이터의 출력, 입력을 통한 비지니스 로직 구성과 유저가 사용하는 유저 인터페이스를 개발한다.
프론트엔드 개발자가 되려면?
웹 퍼블리싱(HTML, CSS, javascript)에 대한 공부는 물론이고, UI/UX와 네트워크에 대한 공부를 해야한다.
프론트엔드의 네트워크
협업을 하기 위해서는 협업하는 사람의 직무를 어느정도 이해하고 있어야 협업하기가 수월하듯, 프론트엔드 개발자도 백엔드 개발도 어느정도 알아둘 필요는 있다. 그 중에서 필수적으로 알아야하는 부분은 바로 네트워크다.
프론트엔드가 갖춰야 할 기술적 소양
HTML, CSS, javascript는 웹 퍼블리셔의 핵심 역량으로, 프론트엔드 개발자가 옵션으로 가지고 있으면 좋은 기술이다.
1. 네트워크 (Network)
2. 버전 관리 (Version Control)
3. 웹 프론트 프레임워크 (Web Front Framework)
4. modern javascript
✨ 10월 27일 (수)
📰 [React] CORS요..? 제 잘못,,, 인가요?
HTTP 리소스 요청 시에 자주 발생하는 CORS에러에 대해 프론트엔드 개발자가 백엔드 개발자에게 확인을 요청하기 전 확인해볼 수 있는 것들에 대한 내용이다.
헷갈리지 않는 기본 요청 보일러플레이트 만들어 놓기
기본적으로 작성해 둔 axios 보일러플레이트를 바탕으로 하나씩 차근차근 작업해 나간다.
axios는 XMLHttpRequest 빌드인 객체에서 사용 가능한 HTTP 요청의 대부분을 지원한다.따라서 제일 기본인 GET 요청을 바탕으로 무료로 JSON 데이터를 제공하고 있는 URL에 GET 요청을 보내 기본적으로 HTTP 통신이 가능한 상황인 지 파악해야 한다.
URL은 기본으로
진행 중인 프로젝트의 백엔드 도메인으로 URL을 바꿔서 적용해본다.
MERN 스택(Mongo Express React Node)과 같이 모든 서버가 같은 node.js 환경에서 두 개의 터미널을 열어 로컬 환경에서 작업할 수 있는 것은 아니다. 따라서 로컬에서 https로 배포되어 있는 서버에 요청을 보내야하는 상황이기 때문에 필히 CORS가 발생할 수밖에 없다.
따라서 일종의 보험을 깔아두는 것처럼, 프론트에서 할 수 있는 최대한의 오픈 마인드를 갖추는 것이 필요합니다.
config 설정하기
config로 설정할 수 있는 프로퍼티는 다음과 같다.
config를 설정해준 뒤, axios 요청에 함께 넣어준다.
✨ 10월 28일 (목)
📰 코딩 테스트에서 C++과 파이썬이 유리한 까닭은?
- 파이썬은 쉬우면서도 활용도가 높아 기업이나 대학원 연구 과정에서 파이썬을 많이 사용한다.
- 최근 코딩 테스트 유형을 보면 변칙적이고 다양한 유형이 등장하고 있는 터라 쉬우면서 변칙적인 유형에 대응하기 쉬운 파이썬이 코딩 테스트에 유리할 수 있습니다.
- 파이썬은 C++나 자바에 비해 코드가 짧고 직관적으로 문제를 풀 수 있습니다. 또한 몇몇 알고리즘을 구현할 때는 라이브러리를 추가할 필요 없이 소스코드를 작성할 수 있다.
- 하지만 알고리즘 대회를 준비하기 위해서는 실행 시간이 짧은 C++를 선택하는 것이 좋다.
- 실제 설문조사에 따르면 알고리즘 문제 풀이에 유리한 언어는 C++, 프로그램 개발에 유리한 언어는 파이썬이 높은 비중을 차지했다.
✨ 10월 29일 (금)
📰 개발자용 운동팁 5가지
- 기술 블로그는 아니지만 요즘 하루 종일 앉아있어서 몸이 말을 듣지 않는다.
- 추천 영상도 포함되어 있으니 찾아 보기 편하다. 나의 경우 가슴 스트레칭이 도움이 되었다.
요약
- 코어힘을 키우자
- 가슴 스트레칭을 하자
- 등빨을 키우자
- 하체충이 되자
- 손목도 챙기자
✨ 10월 30일 (토)
📰 그런 개발자로 괜찮은가 - ‘문화’ 편
코드리뷰
리뷰이(Reviewee)
- 최대한 설명을 잘 적어서 리뷰하는 데 도움을 줄 수 있어야 한다.
- 최대한 작은 단위로 리뷰를 요청해야 한다.
- 최대한 코드 리뷰 받는 부분과 의존성이 없도록 작업이 돼야 하며 정중하게 리뷰어에게 ‘부탁’을 해야 한다.
- 리뷰어의 리뷰는 “지적” 이 아니라 “함께 작업하는 코드에 대한 조언”으로 받아들여야 한다.
리뷰어(Reviewer)
- 최대한 정성껏 리뷰를 한다.
- 최대한 유연한 멘트로 코드 리뷰를 해야 한다.
공유
- 공유의 목적은 자신이 했던 부분들을 ‘다시 정리’함으로써 내 것으로 만드는 과정이다.
- 무엇을 공유해야 하지 모를 땐, 아주 사소하게라도 오늘 알게 되었던 새로운 지식을 적어보는 습관을 길렀으면 한다.
개발 관점에서의 시야
- 모든 직군들이 일정과 스펙 협의가 끝나고 안정적으로 충분한 테스트를 거친 다음 서비스 릴리스가 돼야 하지만. 그렇지 않은 경우가 많다.
- ‘기술 부채’는 점점 커지고 무서워서 코드를 건드리지 못하다 결국 하나둘 팀을 떠나게 되는 안타까운 모습이 발생한다.
- 아무리 바빠도, 개발자는 개발 관점에서의 시야를 놓쳐서는 안 된다.
✨ 10월 31일 (일)
📰 글자 4개로 리액트 컴포넌트를 최적화하는 방법
useState의 지연 초기화
두 코드의 차이점은 상태 초기화 부분이다. 첫 번째 예제는 localStorage에서 값을 찾아 정수로 파싱한 다음 count 상태의 초기 값으로 설정한다.
두 번째 예제는 함수를 인자로 넘긴다는 점을 제외하면 첫번째 예제와 유사하다. 인자로 넘기는 함수는 첫번째 예제처럼 localStorage에서 검색한 값을 정수로 파싱하여 반환한다.
return문을 명시하지 않아도 암묵적으로 값을 반환하는 화살표 함수의 특징 덕분에 첫 번째 예제에서 글자 4개(공백 포함)만 추가하여 두 번째 예제를 만들 수 있다. 또한 초기 값을 얻기 위해 수행하는 작업에 따라, 이 글자 4개만 추가하여 리액트 함수 컴포넌트의 성능을 향상시킬 수 있다.
첫 번째 예제에서는 리렌더링이 발생할 때마다 localStorage에서 값을 찾는다. 하지만 만약 최초 렌더링 시에만 값을 찾아도 된다면, 불필요한 계산을 하고 있는 것이다. 반면, 두 번째 예제는 지연 초기화를 사용하여 불필요한 계산을 방지할 수 있다.
안녕하세요
|
개발자 문현준입니다.

Latest Posts



